Summary
The goal of this post is to implement bandwidth limiting for docker containers running on the same host.
The tools and technologies I’m going to use to achieve the task are:
- Traffic Control (TC)
- Hierarchical Token Bucket (HTB)
- Intermediate Functional Block (IFB)
- extended Berkeley Packet Filter (eBPF)
Given that all the technologies are very mature and there are tons of good articles on the Internet to explain them, I will only list articles I found useful for me to understood the concepts and focus more on the implementation that puts the technologies together. Plus, these days I’m sure ChatGPT does a better job explaining the concepts than me.
Concepts
Traffic Control (TC)
This doc is a comprehensive
document about the concept of traffic control in general. Though it also
briefly talks about the software and tools used for traffic control, the best
way to learn how to use tc utility is man
tc(8).
We’ll use tc for traffic shaping / bandwidth limiting.
Hierarchical Token Bucket (HTB)
HTB is one of the classful queue disciplines (qdisc) of tc. This
doc is a very good
introduction of HTB, covering both the theory and the application. man
tc-htb(8) has more
detailed information about how to use HTB in tc.
HTB is the qdisc we’ll choose when using tc for traffic shaping.
Intermediate Functional Block (IFB)
Traffic Shaping v.s. Traffic Policing
The tc man page mentions
that traffic shaping occurs on egress and traffic policing happens on
ingress.
The following diagram explains the difference between traffic shaping and policy.
Suppose our goal is to do traffic shaping on both egress and ingress, which
cannot be achieved by tc alone, then we will need the help of IFB
(Intermediate Functional
Block).
The idea is simple: we redirect the ingress traffic to the special IFB interface and configure TC to do traffic shaping on the egress side of the IFB device.
There is also a very good stackexchange question about how IFB
works.
extended Berkeley Packet Filter (eBPF)
The eBPF documents is no doubt the best start point of eBPF. eBPF can be used as a programmable classifier and actions for ingress/egress queueing disciplines.
We’ll use a BPF_PROG_TYPE_SCHED_CLS type BPF program and BPF maps to achieve
traffic classification.
Implementation
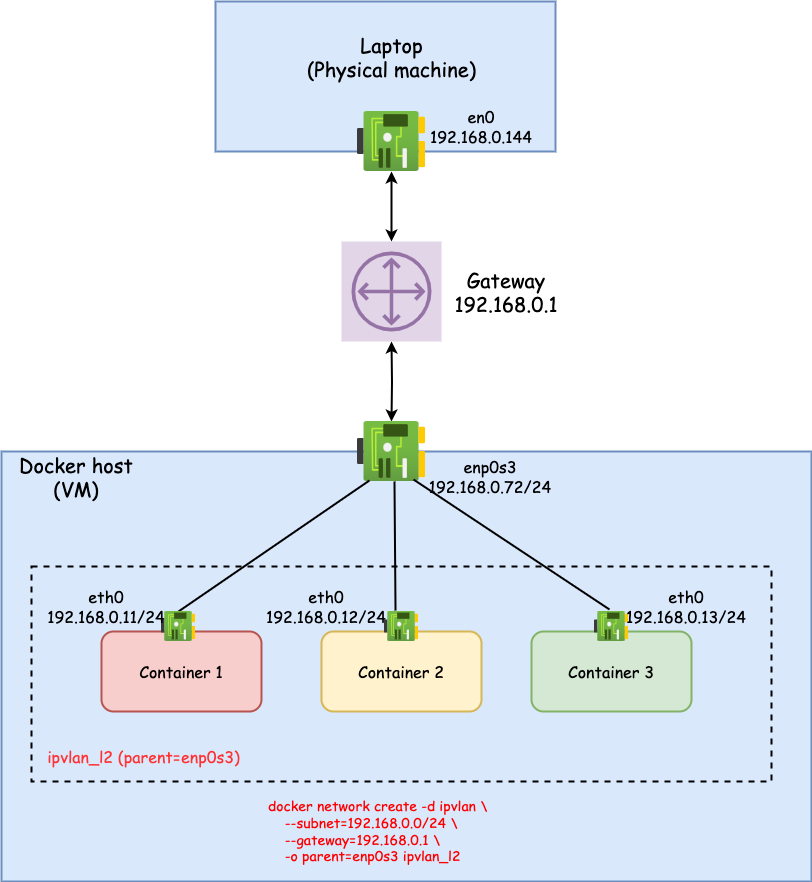
Environment
The experiments run on a VirtualBox VM with the following software
- Ubuntu 22.04
- Linux kernel version 6.2.0-37-generic
- Docker version 24.0.5, build ced0996
- iproute2-5.15.0 (the package that includes
tc)
The VM network is
bridged, in
which it looks to the host system as though the VM were physically connected
using a network cable. My home network is 192.168.0.0/24 and the laptop where
the experientments will run has an IP 192.168.0.144. The VM has an IP
192.168.0.72 and its link speed is 1000Mb/s.
Create a Container Network
First, we create an L2 ipvlan
network to launch containers
into. The containers will be in the same 192.168.0.0/24 network as the VM.
$ docker network create -d ipvlan \
--subnet=192.168.0.0/24 \
--gateway=192.168.0.1 \
-o parent=enp0s3 ipvlan_l2
Launch docker containers
$ cat Dockerfile
FROM ubuntu:22.04
RUN apt-get update && \
apt-get install -y net-tools iproute2 netcat dnsutils curl iputils-ping tcpdump iperf3
# Build container image
$ sudo docker build -t tc_htb_demo .
# Launch containers (in separate terminals)
$ sudo docker run -it --name container1 --rm --network ipvlan_l2 --ip=192.168.0.11
$ sudo docker run -it --name container2 --rm --network ipvlan_l2 --ip=192.168.0.12
$ sudo docker run -it --name container3 --rm --network ipvlan_l2 --ip=192.168.0.13
Default Bandwidth Limiting
First, let’s try sending some traffic when there is no explict bandwidth
limiting configured. By default, fq_codel (Fair Queuing Controlled Delay)
qdisc is used.
$ tc qdisc show dev enp0s3
qdisc fq_codel 0: root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
On laptop 192.168.0.144, we start 3 iperf servers on the laptop with port
5201, 5202, 5203.
$ iperf3 -s -p 5201
$ iperf3 -s -p 5202
$ iperf3 -s -p 5203
The 3 containers then send traffic to the 3 ports respectively.
# container 1 (192.168.0.11)
# iperf3 -c 192.168.0.144 -p 5201
# container 2 (192.168.0.12)
# iperf3 -c 192.168.0.144 -p 5202
# container 3 (192.168.0.13)
# iperf3 -c 192.168.0.144 -p 5203
Here is the result:
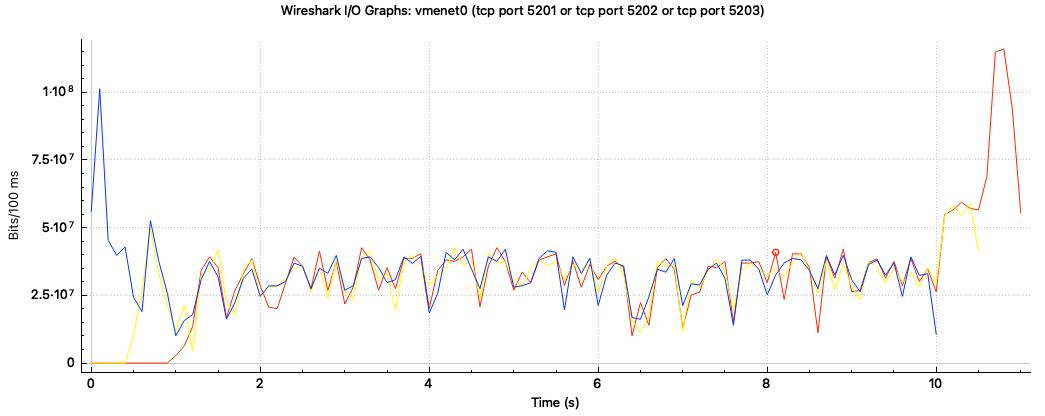
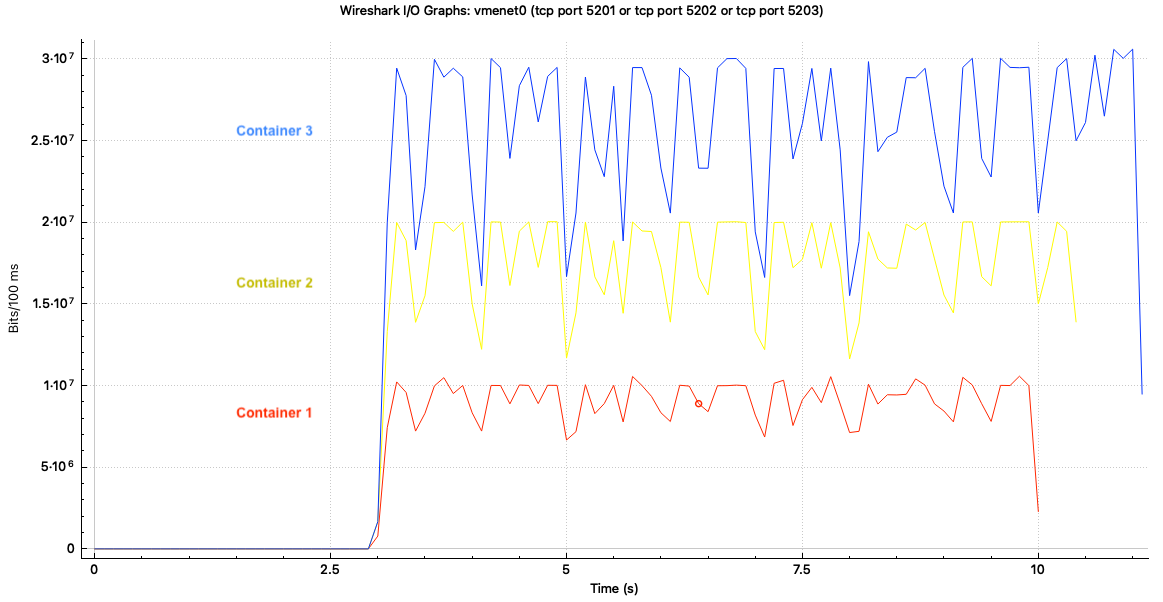
We can see that with the default qdisc, each container get roughly 1/3 of the total 1000Mb/s bandwidth.
HTB Bandwidth Limiting
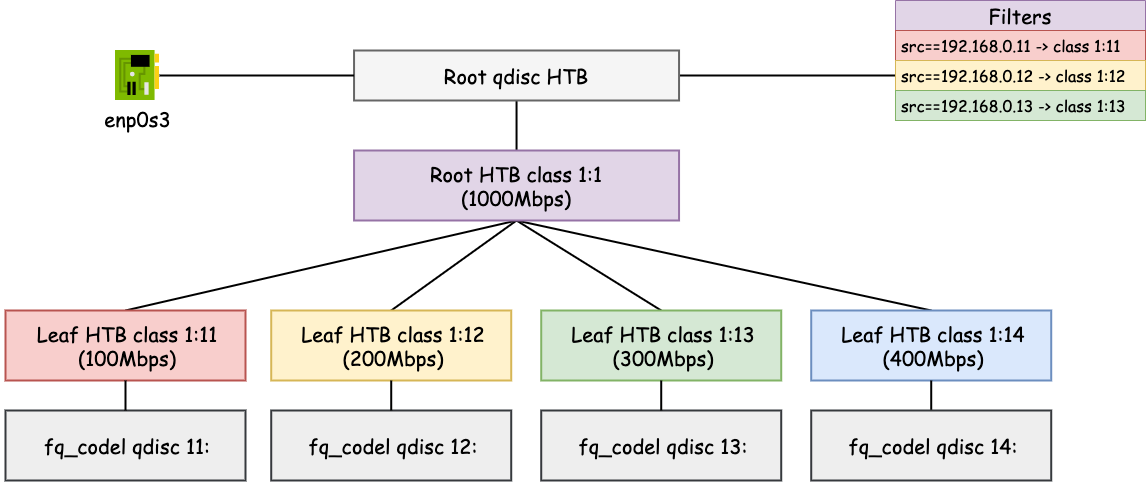
Next, we set up HTB qdisc and class to achieve the following:
- Container 1 (
192.168.0.11) is limited to a 100Mbps bandwidth. - Container 2 (
192.168.0.12) is limited to a 200Mbps bandwidth. - Container 3 (
192.168.0.13) is limited to a 300Mbps bandwidth. - The rest of the host limited to the remaining 400Mbps bandwidth.
# Replace the root qdisc with HTB qdisc. The default class has minor id 14
tc qdisc replace dev enp0s3 root handle 1: htb default 14
# Add the root class with the max bandwidth on the interface
tc class add dev enp0s3 parent 1: classid 1:1 htb rate 1000mbit
# Add the leaf class with minor id 11 and bandwidth 100Mb/s
tc class add dev enp0s3 parent 1:1 classid 1:11 htb rate 100mbit ceil 100mbit
# Add the leaf class with minor id 12 and bandwidth 200Mb/s
tc class add dev enp0s3 parent 1:1 classid 1:12 htb rate 200mbit ceil 200mbit
# Add the leaf class with minor id 13 and bandwidth 300Mb/s
tc class add dev enp0s3 parent 1:1 classid 1:13 htb rate 300mbit ceil 300mbit
# Add the leaf class with minor id 14 and bandwidth 400Mb/s
tc class add dev enp0s3 parent 1:1 classid 1:14 htb rate 400mbit ceil 400mbit
# Add a fq_codel qdisc to leaf classes
tc qdisc add dev enp0s3 parent 1:11 handle 11: fq_codel
tc qdisc add dev enp0s3 parent 1:12 handle 12: fq_codel
tc qdisc add dev enp0s3 parent 1:13 handle 13: fq_codel
tc qdisc add dev enp0s3 parent 1:14 handle 14: fq_codel
Note that the last steps to add fq_codel qdiscs to leaf classes is optional. According
to man tc-htb,
Within the one HTB instance many classes may exist. Each of these classes contains another qdisc, by default tc-pfifo(8).
This means the default qdisc for each leaf class is the simplest pfifo, which
is not as good as fq_codel in terms of fairness.
Now we have set up the following hierarchy.
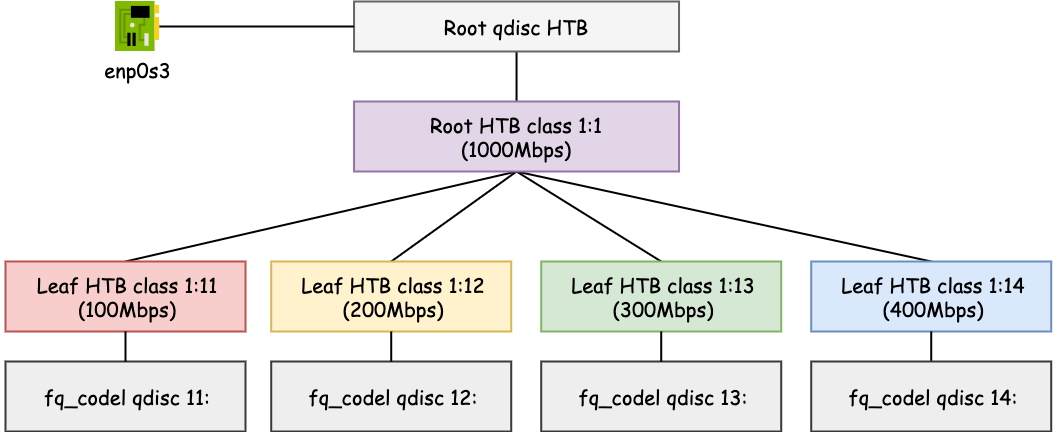
NOTE: At this point, if we send traffic from any of the 3 containers or
from the VM to the iperf3 server running on the laptop, their bandwidth will
be limited at 400Mbps. Because all traffic is currently unclassified and hence
fall into the default class 14.
Therefore, we now need to add some filters to classify the traffic based on container IP so that they fall into the right buckets.
tc filter add dev enp0s3 protocol ip prio 1 parent 1: u32 match ip src 192.168.0.11 classid 1:11
tc filter add dev enp0s3 protocol ip prio 1 parent 1: u32 match ip src 192.168.0.12 classid 1:12
tc filter add dev enp0s3 protocol ip prio 1 parent 1: u32 match ip src 192.168.0.13 classid 1:13
Now if we run the previous iperf experiment, we will get
We can also see the statistics by using tc -s:
class htb 1:1 root rate 1Gbit ceil 1Gbit burst 1375b cburst 1375b
Sent 620550772 bytes 409962 pkt (dropped 0, overlimits 5356 requeues 0)
backlog 0b 0p requeues 0
lended: 0 borrowed: 0 giants: 0
tokens: 176 ctokens: 176
class htb 1:11 parent 1:1 leaf 11: prio 0 rate 100Mbit ceil 100Mbit burst 1600b cburst 1600b
Sent 107104918 bytes 70758 pkt (dropped 0, overlimits 2485 requeues 0)
backlog 0b 0p requeues 0
lended: 2603 borrowed: 0 giants: 0
tokens: 1917 ctokens: 1917
class htb 1:12 parent 1:1 leaf 12: prio 0 rate 200Mbit ceil 200Mbit burst 1600b cburst 1600b
Sent 204780628 bytes 135273 pkt (dropped 0, overlimits 3655 requeues 0)
backlog 0b 0p requeues 0
lended: 3829 borrowed: 0 giants: 0
tokens: 958 ctokens: 958
class htb 1:13 parent 1:1 leaf 13: prio 0 rate 300Mbit ceil 300Mbit burst 1537b cburst 1537b
Sent 308660726 bytes 203886 pkt (dropped 0, overlimits 4734 requeues 0)
backlog 0b 0p requeues 0
lended: 4800 borrowed: 0 giants: 0
tokens: 628 ctokens: 628
class htb 1:14 parent 1:1 leaf 14: prio 0 rate 400Mbit ceil 400Mbit burst 1600b cburst 1600b
Sent 4500 bytes 45 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
lended: 45 borrowed: 0 giants: 0
tokens: 473 ctokens: 473
In this experiment, we set rate == ceil to have strict bandwidth limiting. We could also set ceil > rate to allow borrowing from the parent class. Then you will see a non-zero “borrowed” in the statistics. I’ll leave that to the reader.
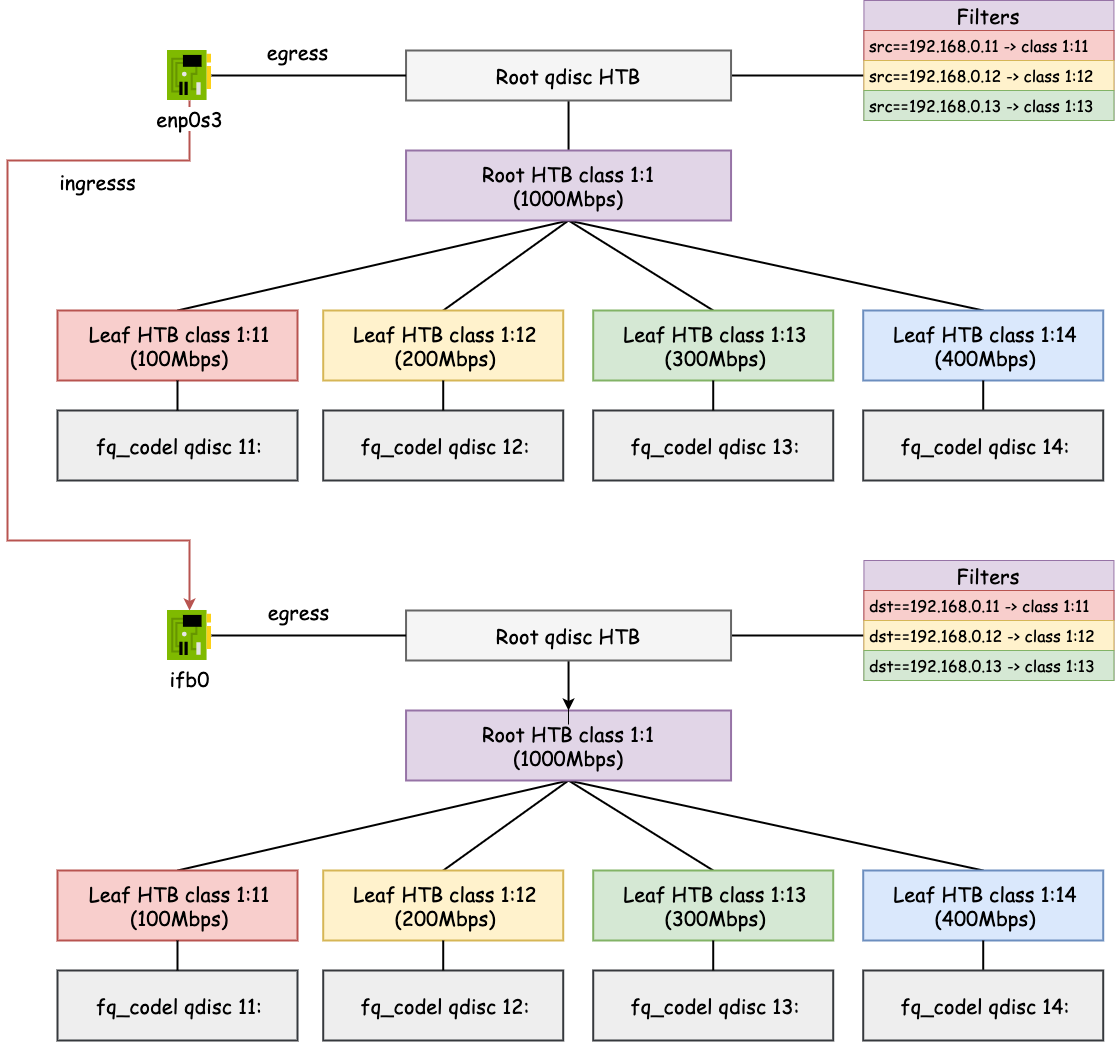
Ingress Bandwidth Limiting
In the previous experiment, the traffic is sent from the container to the
remote server. In other words, the bandwidth limiting happens on egress. If in
container 1, we run iperf3 -c 192.168.0.144 --reverse, which changes the
traffic direction from the server to the client, then we will see that the bit
rate can reach at the max 1000Mbps. Because there is no bandwidth limiting on
the ingress side.
In order to achieve bandwidth limiting on ingress, first, we set up an IFB
device ifb0 and redirect ingress traffic on enp0s3 to ifb0. See man
tc-mirred for more
information.
# Load IFB module
modprobe ifb
# Set up the ifb0 link
ip link set ifb0 up
# Add an ingess qdisc to enp0s3
tc qdisc add dev enp0s3 handle ffff: ingress
# Redirect ingress traffic on enp0s3 to ifb0
tc filter add dev enp0s3 parent ffff: \
protocol all matchall \
action mirred egress redirect dev ifb0
Then we can set up HTB on ifb0 interface similar to enp0s3. The
configuration is almost identical except that the filters need to match the
dst instead of src IPs.
# Replace the root qdisc with HTB qdisc. The default class has minor id 14
tc qdisc replace dev ifb0 root handle 1: htb default 14
# Add the root class with the max bandwidth on the interface
tc class add dev ifb0 parent 1: classid 1:1 htb rate 1000mbit
# Add the leaf class with minor id 11 and bandwidth 100Mb/s
tc class add dev ifb0 parent 1:1 classid 1:11 htb rate 100mbit ceil 100mbit
# Add the leaf class with minor id 12 and bandwidth 200Mb/s
tc class add dev ifb0 parent 1:1 classid 1:12 htb rate 200mbit ceil 200mbit
# Add the leaf class with minor id 13 and bandwidth 300Mb/s
tc class add dev ifb0 parent 1:1 classid 1:13 htb rate 300mbit ceil 300mbit
# Add the leaf class with minor id 14 and bandwidth 400Mb/s
tc class add dev ifb0 parent 1:1 classid 1:14 htb rate 400mbit ceil 400mbit
# Add a fq_codel qdisc to leaf classes
tc qdisc add dev ifb0 parent 1:11 handle 11: fq_codel
tc qdisc add dev ifb0 parent 1:12 handle 12: fq_codel
tc qdisc add dev ifb0 parent 1:13 handle 13: fq_codel
tc qdisc add dev ifb0 parent 1:14 handle 14: fq_codel
# Add filters to classif ingress traffic
tc filter add dev ifb0 protocol ip prio 1 parent 1: u32 match ip dst 192.168.0.11 classid 1:11
tc filter add dev ifb0 protocol ip prio 1 parent 1: u32 match ip dst 192.168.0.12 classid 1:12
tc filter add dev ifb0 protocol ip prio 1 parent 1: u32 match ip dst 192.168.0.13 classid 1:13
Now of we run the --reverse test again, we get:
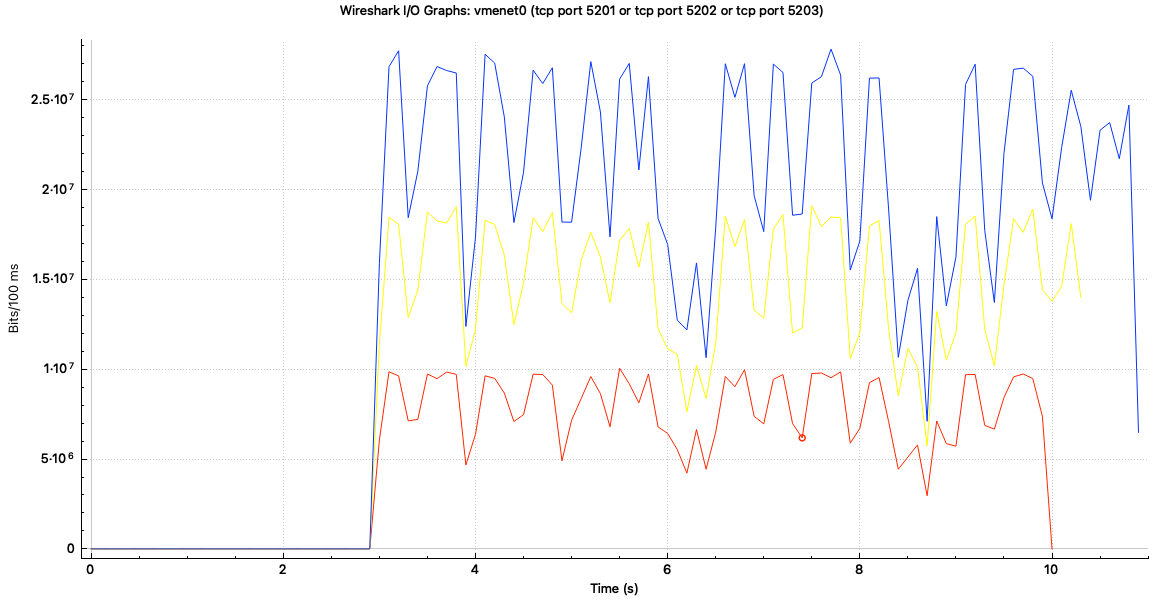
The throughput is lower than egress. I am guessing it has something to do with traffic redirection to IFB device but didn’t look into it.
BPF Filter
In the experiment above, we used the u32
filter to classify the
traffic. An alternative is to use BPF filters. Using BPF is more flexible and
easier to reason about when the filtering rule gets complex.
Let’s write a BPF program that classify the traffic based on IP addresses by looking up a hash map from IP address to class id. The map needs to be updated by the control plane.
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/pkt_cls.h>
#include <bpf/bpf_endian.h>
#include <bpf/bpf_helpers.h>
#include <string.h>
struct ipv4_key {
__be32 addr;
};
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, struct ipv4_key);
__type(value, __u16);
__uint(max_entries, 1024);
__uint(pinning, LIBBPF_PIN_BY_NAME);
} class_by_ipv4 SEC(".maps");
int classify_ingress_ipv4(struct __sk_buff *skb) {
__u16* classid;
struct iphdr iphdr;
struct ipv4_key key;
// Get the IP header
if (bpf_skb_load_bytes(skb, ETH_HLEN, &iphdr, sizeof(iphdr)) < 0) {
return TC_ACT_SHOT;
}
// Copy the destination IPv4 address to the key
memcpy(&key.addr, &iphdr.daddr, sizeof(key.addr));
// Look up the class id by source IPv4
classid = bpf_map_lookup_elem(&class_by_ipv4, &key);
if (classid) {
skb->tc_classid = TC_H_MAKE(1 << 16, *classid);
}
return TC_ACT_OK;
}
SEC("classifier_ingress")
int classify_ingress(struct __sk_buff *skb) {
switch (skb->protocol) {
case __bpf_constant_htons(ETH_P_IP):
return classify_ingress_ipv4(skb);
// TODO: Support IPv6
case __bpf_constant_htons(ETH_P_IPV6):
return TC_ACT_OK;
default:
return TC_ACT_OK;
}
}
int classify_egress_ipv4(struct __sk_buff *skb) {
__u16* classid;
struct iphdr iphdr;
struct ipv4_key key;
// Get the IP header
if (bpf_skb_load_bytes(skb, ETH_HLEN, &iphdr, sizeof(iphdr)) < 0) {
return TC_ACT_SHOT;
}
// Copy the source IPv4 address to the key
memcpy(&key.addr, &iphdr.saddr, sizeof(key.addr));
// Look up the class id by source IPv4
classid = bpf_map_lookup_elem(&class_by_ipv4, &key);
if (classid) {
skb->tc_classid = TC_H_MAKE(1 << 16, *classid);
}
return TC_ACT_OK;
}
SEC("classifier_egress")
int classify_egress(struct __sk_buff *skb) {
switch (skb->protocol) {
case __bpf_constant_htons(ETH_P_IP):
return classify_egress_ipv4(skb);
// TODO: Support IPv6
case __bpf_constant_htons(ETH_P_IPV6):
return TC_ACT_OK;
default:
return TC_ACT_OK;
}
}
char __license[] SEC("license") = "GPL";
Then we compile the program and attach the filter to enp03s and ifb0:
# Compile the BPF program
$ clang -O2 -g target bpf -c bpf_filter.c -o bpf_filter.o
# Delete existing filters
$ sudo tc filter del dev enp0s3
$ sudo tc filter del dev ifb0
# Attach BPF filters
$ sudo tc filter add dev enp0s3 parent 1: bpf direct-action \
obj bpf_filter.o \
sec classifier_egress \
classid 1:1 \
$ sudo tc filter add dev ifb0 parent 1: bpf direct-action \
obj bpf_filter.o \
sec classifier_ingress \
classid 1:1
We also need to put the ip to class id mappings to the BPF map. Note that the key and the value are in network order.
$ sudo bpftool map update pinned /sys/fs/bpf/tc/globals/class_by_ipv4 \
key 192 168 0 11 \ # IP
value 0x11 0x00 # Class ID
$ sudo bpftool map update pinned /sys/fs/bpf/tc/globals/class_by_ipv4 \
key 192 168 0 12 \ # IP
value 0x12 0x00 # Class ID
$ sudo bpftool map update pinned /sys/fs/bpf/tc/globals/class_by_ipv4 \
key 192 168 0 13 \ # IP
value 0x13 0x00 # Class ID
Now if we do the same iperf tests, we should be able to achieve the same
result.
Summary
In this experiment, we ran multiple commands to achieve bandwidth limiting for individual docker containers.
In practice, all of we we have configured should be done by a container management software programmably. Pseudocode:
# Run once for the host setup
set_up_docker_host(max_bandwidth) {
################# egress #################
# Replace the root qdisc with HTB qdisc.
tc qdisc replace dev enp0s3 root handle 1: htb
# Add the root class with the max bandwidth on the interface
tc class add dev enp0s3 parent 1: classid 1:1 htb rate $max_bandwidth
################# ingress #################
# Load IFB module
modprobe ifb
# Set up the ifb0 link
ip link set ifb0 up
# Add an ingess qdisc to enp0s3
tc qdisc add dev enp0s3 handle ffff: ingress
# Redirect ingress traffic on enp0s3 to ifb0
tc filter add dev enp0s3 parent ffff: \
protocol all matchall \
action mirred egress redirect dev ifb0
}
# Replace the root qdisc with HTB qdisc.
tc qdisc replace dev ifb0 root handle 1: htb
# Add the root class with the max bandwidth on the interface
tc class add dev ifb0 parent 1: classid 1:1 htb rate $max_bandwidth
# Run for each container setup
set_up_container_bandwidth_limiting(class_id, ip, bandwidth_limit) {
################# egress #################
tc class add dev enp0s3 parent 1:1 classid 1:$class_id htb \
rate $bandwidth_limit ceil $bandwidth_limit
################# ingress ################
tc class add dev ifb0 parent 1:1 classid 1:$class_id htb \
rate $bandwidth_limit ceil $bandwidth_limit
################# BPF map ################
bpftool map update pinned /sys/fs/bpf/tc/globals/class_by_ipv4 \
key $ip value $class_id
}
