Mini Container Series Part 2
[This is the third article in this series. The previous one is here].
Summary
Next, we are going to make the container think that it is the only process running in the system. This can be achieved by utilizing PID namespace. Personally, I found that PID namespace is much easier to understand than mount namespace. So, if you survived mount namespace, then you will find PID namespace very easy to grasp.
Let’s get started with some basics.
Basics
proc filesystem
The proc filesystem (procfs) provides information about processes in the format of files. It can be seen as an interface to internal data structures in the kernel.
Typically, procfs is mounted at /proc. Recall that in the last article, the final step of preparing the filesystem for the container was to mount the procfs. Without /proc, utilities like ps won’t work. And last time we mounted /proc because we would like to examine /proc/self/mountinfo file.
Now you know why I talked about mount namespace first. Because without filesystem isolation, mounting the procfs to /proc will affect the host. For more details about each file under /proc/PID/, see man proc(5).
PID namespace
As the name implies, PID namespaces isolate the process ID numbers. With PID namespaces, we may have
- different processes in different PID namespaces with the same process ID and
- one process referenced by different PIDs in different namespaces.
Unlike mount namespace, PID namespaces
- are hierarchically nested in parent-child relationships [3]
- Recall that even if one mount namespace is cloned from another, it doesn’t make them parent and child. They are more like peers and can decide the propagation type of each mount point individually.
- don’t copy the PIDs in the parent namespace to the child.
- Instead, a new PID namespace initially has no PIDs and the first process running in the namespace will have PID 1.
In a PID namespace, one process can only see all other processes in
- the same PID namespace and
- the namespace’s descendant namespaces.
But it cannot see processes in
- its ancestor namespaces and
- its sibling namespaces
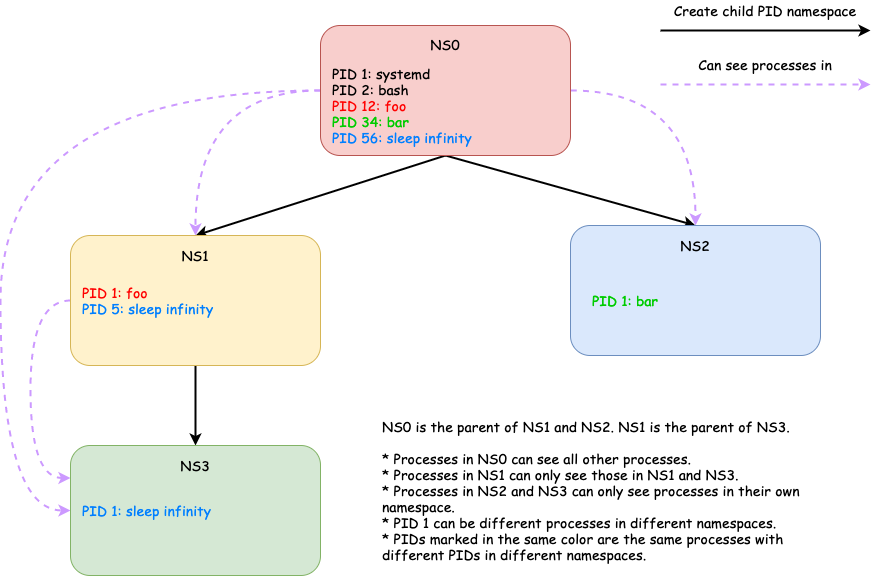
Similar to mount namespace, a new PID namespace can be created by calling clone() or unshare() with the CLONE_NEWPID flag. However, different from unshare(CLONE_NEWNS), unshare(CLONE_NEWPID) won’t move the calling process into the new namespace. Instead, the first child created by the calling process will have the process ID 1 and will assume the role of init(1) in the new namespace[2]. (I will not cover init process in this article but may talk about it in the future.)
Why is that?
The reason is to avoid breaking the assumption of a process’s PID being constant. If an existing process enters a new namespace, then the return value of getpid() may change. That means a program like the following will not work as expected.
1
2
3
4
5
6
7
8
9
10
int pid = getpid(); // <-- Called before entering new PID NS
...
// Suppose unshare(CLONE_NEWPID) moves current process to a new PID NS
unshare(CLONE_NEWPID);
// If you call getpid() now, the return value may be different than before
// You'll either read nothing or falsely read another process's stats.
sprintf(str, "/proc/%d/stat", my_pid);
read_file(str);
Therefore, once a process is created, its PID namespace membership can never be changed.
mini container: Process isolation
The change is very easy, we only need to pass a CLONE_NEWPID flag when spawning the container process. In other words, we want to call something like fork(CLONE_NEWPID), which creates a new PID namespace while cloning the process. However, such a glibc wrapper doesn’t exist - fork() doesn’t take any parameters while clone() takes a function and a stack then runs that function in that stack in the child process. Both are not exactly what we want. Therefore, we need the raw syscall clone.
(Side note: See this article for a debate on getting proper wrappers into glibc)
According to man clone(2), the raw system call interface of clone on x86-64 is:
1
2
3
long clone(unsigned long flags, void *stack,
int *parent_tid, int *child_tid,
unsigned long tls);
So we adapt our code to use the raw clone syscall and pass CLONE_NEWPID to it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int cpid = syscall(SYS_clone, SIGCHLD | CLONE_NEWNS | CLONE_NEWPID);
if (cpid == -1) {
errExit("clone");
}
if (cpid == 0) {
setupFilesystem();
execv(argv[1], &argv[1]);
} else {
if (waitpid(cpid, NULL, 0) == -1) {
errExit("waitpid");
}
}
return 0;
See this commit for complete source code.
Test
Now we can do some tests.
Build
1
2
3
4
$ mkdir build
$ cd build
$ cmake ..
$ make
Run “/bin/bash” in a container
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
$ sudo ./mini_container --rootfs /tmp/mini_container/rootfs "/bin/bash" --pid
[Agent] The container's pid is 24462
[Agent] Agent pid is 24461
[Container] Running command: /bin/bash
# ps thinks there are only 2 processes in the system
[root@hechaol-vm /]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 12028 3248 ? S 02:45 0:00 /bin/bash
root 10 0.0 0.0 44636 3488 ? R+ 02:47 0:00 ps aux
# Start a background process
[root@hechaol-vm /]# sleep infinity &
[1] 11
[root@hechaol-vm /]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 12028 3268 ? S 02:45 0:00 /bin/bash
root 11 0.0 0.0 23028 1396 ? S 02:48 0:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep infinity
root 12 0.0 0.0 44636 3372 ? R+ 02:48 0:00 ps aux
Note:
- The container thinks its PID is 1 while the agent thinks its PID is 24462.
pscommand in the container thinks there are only 2 processes running in the system. It can’t see other processes on the host.
In a different shell on the host
1
2
3
4
5
6
7
8
9
10
$ ps aux | grep /bin/bash
root 24460 0.0 0.1 20556 4700 pts/2 S 18:45 0:00 sudo ./mini_container --rootfs /tmp/mini_container/rootfs /bin/bash --pid
root 24461 0.0 0.0 6684 1820 pts/2 S 18:45 0:00 ./mini_container --rootfs /tmp/mini_container/rootfs /bin/bash --pid
root 24462 0.0 0.0 12028 3268 pts/2 S+ 18:45 0:00 /bin/bash
hechaol 24516 0.0 0.0 17672 656 pts/1 R+ 18:51 0:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn --exclude-dir=.idea --exclude-dir=.tox /bin/bash
$ ps aux | grep "sleep infinity"
root 24476 0.0 0.0 23028 1396 pts/2 S 18:48 0:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep infinity
hechaol 24603 0.0 0.0 17676 724 pts/1 S+ 18:52 0:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn --exclude-dir=.idea --exclude-dir=.tox sleep infinity
Note that both /bin/bash and sleep running in the container are visible to the host.
Kill a process running in the container from the host
Note that the host can not only see but also manage processes running in the container. For example, we can kill the sleep process inside the container from the host.
1
$ sudo kill -9 24476
In the container
1
2
3
4
5
[root@hechaol-vm /]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 12028 3268 ? S 02:45 0:00 /bin/bash
root 13 0.0 0.0 44636 3420 ? R+ 02:54 0:00 ps aux
[1]+ Killed sleep infinity
Awesome! Now we have a container with its own filesystem and process space. We will continue isolating other resources in next articles.
Resources
[1] man pid_namespace(7)
[2] man unshare(2)
[3] Namespaces in operation, part 3: PID namespaces
[4] man proc(5)
[5] Namespaces in operation, part 4: more on PID namespaces
Comments powered by Disqus.