Rocket I/O
TL;DR
Rocket I/O is an async runtime with the support of various asynchronous I/O back-end such as io_uring. The goal of Rocket I/O is to make programming with asynchronous I/O simpler and more intuitive. The code is available on Github.
Overview
As we know, input and output (I/O) operations on a computer can be extremely slow comparing to running CPU instructions. A simple approach of performing an I/O operation is to block the current execution until the I/O is complete (i.e. synchronous I/O). However, this can be a waste of system resources because the CPU does nothing useful while waiting for I/O completion. A better approach would be asynchronous I/O, which means after issuing an I/O request, instead of waiting for it to complete, the CPU can spend time processing instructions not depending on the I/O result.
There are many options to implement asynchronous I/O on Linux. For example, we could use I/O multiplexing mechanisms such as select, poll, epoll described in my previous post. Or we can use asynchronous interfaces provided by the kernel such as aio or io_uring. However, each option has its own distinct way of supporting asynchronous I/O, which is usually not that intuitive and straightforward. A developer needs to read their documentation thoroughly to figure out the correct usage. Hence, my friend Andrew and I started a project, Rocket I/O, with the goal of making programming with asynchronous I/O simpler and more intuitive.
Background
I/O
Input and output (I/O) operations usually involves reading from or writing to an device such as a disk (e.g. file I/O) or a remote computer (e.g. socket I/O). An I/O operation is generally much slower than CPU running instructions. Therefore, I/O is usually the bottleneck in an application. It’s like programming. No matter how fast a programmer’s brain runs, their coding speed is only as fast as their typing speed (i.e. I/O speed).
Synchronous I/O v.s. Asynchronous I/O
There are two ways to handle I/O operations: synchronous and asynchronous.
- Synchronous I/O means that once an I/O is requested, the current execution is blocked until the I/O is complete.
- Asynchronous I/O means that after an I/O is requested, the execution can spend time processing data not depending on the I/O result. Later when the I/O is complete, operations depending on the I/O result is resumed.
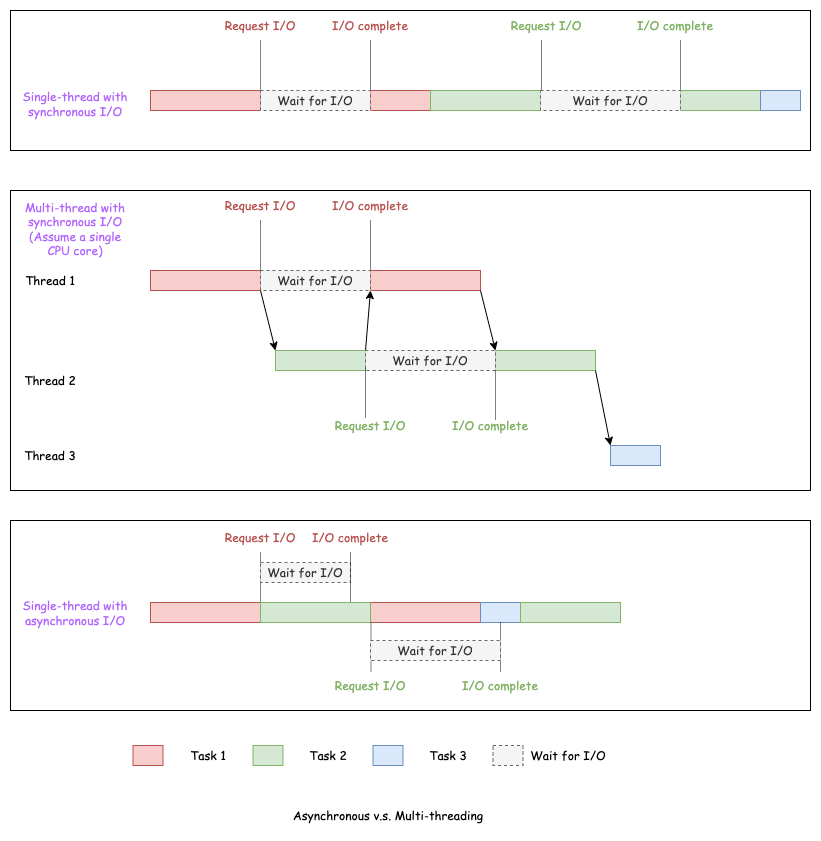
Apparently, asynchronous I/O has the advantage when there are multiple concurrent executions. For example, for a single-threaded server, using asynchronous I/O enables it to serve multiple clients concurrently. Basically, it can process client B’s data while waiting for client A to input data. However, if there is only one client, then there is not much difference between synchronous and asynchronous I/O in terms of performance.
Asynchronous v.s. Multi-threading
This might be a misconception that asynchronous and multi-threading are the same thing, especially for people new to asynchronous programming. Once, I heard an intern saying, “My program is multi-threaded so it’s already asynchronous.” and “The program is single-threaded so it can’t be async.” Both statements are not accurate. Asynchronous and multi-threading and related but not identical concepts.
First of all, “asynchronous” is about whether other operations can run while a single expensive operation (e.g. I/O) is ongoing. “Multi-threading” is about whether multiple tasks can run concurrently. These tasks contain multiple operations, which may or may not include I/O operations. In this sense, “asynchronous” only makes sense when there are blocking operations such as I/O. If a task can run to the end without being blocked by any slow operations, then there is no point of talking about “asynchronous” even if the program is multi-threaded.
Secondly, multi-threading without asynchronous I/O can only achieve “global asynchrony”. By that I mean, for a multi-threaded program on Linux, when one thread is blocked by I/O, it may be preempted in favor of other runnable threads. Later when the I/O is complete, the original thread can be resumed. This is what I call “global asynchrony”. However, from each thread’s point of view, there is no asynchrony because it’s blocked when an I/O is ongoing.
Thirdly, asynchrony doesn’t require multi-threading and can be implemented using a single thread. A good example is a single-threaded echo server implemented using select/poll/epoll. There are tons of examples on the Internet. Our Rocket I/O library is also a single-thread asynchronous runtime, which I will talk more later.
Asynchronous I/O v.s. Non-blocking I/O
The difference between these two concepts is more subtle. My understanding of the subtle difference is,
- Asynchronous I/O means, you make an I/O request and move on with other operations. Later when the I/O is complete, you’re somehow notified with the completion. The example is Linux
aioandio_uring. - Non-blocking I/O means, you check if the I/O is ready and if so, perform the I/O, which is guaranteed to be non-blocking because the data is ready. The example is
select/poll/epoll. I also mentioned it in my previous post thatselect/poll/epollonly guarantees that there is data ready on the file descriptor so that the I/O doesn’t need to wait/block, the I/O operation itself is still synchronous.
In fact, I found that usually people can use these two terms interchangeably without causing confusion.
Fiber
Fiber is a vital component in implementing asynchronous I/O. Wikipedia says “a fiber is a particularly lightweight thread of execution”. And I believe the best way to understand what a fiber is to compare it with thread.
- Threads use preemptive time-slicing, meaning a thread is preempted involuntarily by a scheduler when its time slice is up. Fibers use cooperative context switching, meaning a fiber yields to another fiber voluntarily when it is idle or blocked by I/O.
- Within one process, multiple threads can run. And within one thread, multiple fibers can run.
- Like threads, fibers also share one address space.
- Because fibers are cooperative and yielding voluntarily, synchronization mechanisms like locks can sometimes be unnecessary among fibers. Because they always yield at well-defined boundaries and thus fibers are synchronized implicitly.
This cooperative context switching is the key for an async runtime like Rocket I/O. Basically, when a fiber is requesting an I/O, it knows that the I/O will take a while so it will voluntarily yield to another fiber.
Example in Code
I always believe that the best way of explaining a computer science concept is to show it in code. So I’m going to write a simple task using fiber and thread respectively to show the differences.
The task is actually a question I was once asked in an interview. The question goes, suppose you have one thread that only prints odd numbers and the other thread that only prints even numbers, how do you make them print the sequence 1,2,3,4, …?
pthread example
When using threads, we will use a global number, a conditional variable and two threads. Each thread waits on the conditional variable when the number is not what the thread should print and signals the conditional variable after printing and increasing the number.
main_thread.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
#include <pthread.h>
#include <stdio.h>
#include <stdbool.h>
#include <stdint.h>
#define MAX_NUM 10
pthread_mutex_t mutex;
pthread_cond_t cond;
static int number = 0;
static void* print_num(void* context) {
bool print_odd = (uintptr_t)context;
bool print_even = !print_odd;
pthread_mutex_lock(&mutex);
while(number < MAX_NUM) {
while ((print_odd && number % 2 == 0) || (print_even && number % 2 == 1)) {
pthread_cond_wait(&cond, &mutex);
}
printf("%d ", number);
number++;
pthread_mutex_unlock(&mutex);
pthread_cond_signal(&cond);
pthread_mutex_lock(&mutex);
}
pthread_mutex_unlock(&mutex);
return NULL;
}
int main() {
pthread_t odd_thread, even_thread;
pthread_create(
&odd_thread, /*attr=*/NULL, print_num, /*print_odd=*/(void*)true);
pthread_create(
&even_thread, /*attr=*/NULL, print_num, /*print_odd=*/(void*)false);
pthread_join(odd_thread, /*retval=*/NULL);
pthread_join(even_thread, /*retval=*/NULL);
return 0;
}
To run the program:
1
2
3
$ gcc main_thread.c -o main_thread -lpthread
$ ./main_thread
0 1 2 3 4 5 6 7 8 9 10
fiber example
When using fibers, we no longer need mutex and conditional variable because one fiber can simply yield to the other when the number is not what it should print. The following implementation works on x86_64.
In this simple implementation, a fiber context is nothing but a stack, a program counter and a few registers. When one fiber yields to another, it simple switches these registers to the values of the other fiber.
First, we need some assembly functions to initialize and switching fiber contexts. Knowledge on x86_64 assembly and calling convention is needed to understand the code. Here is a good cheatsheet. In fact, both functions should also save and restore the callee-saved registers but I omitted it for simplicity.
switch.S:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
.global init_run_context
.global switch_run_context
# Initialize a fiber's stack.
# rdi: pointer to the fiber's stack pointer.
# rsi: entry point of the fiber.
init_run_context:
# Save current stack pointer
pushq %rbp
movq %rsp, %rbp
# Get the fiber's stack pointer from rdi
movq (%rdi), %rsp
# Push the entry point address to the fiber's stack.
pushq %rsi
# Update the fiber's stack pointer
movq %rsp, (%rdi)
# Restore current stack pointer
movq %rbp, %rsp
popq %rbp
retq
# Switch context from one fiber to another.
# rdi: pointer to the source fiber's stack pointer.
# rsi: the destination fiber's stack pointer.
switch_run_context:
# rax = return address of the source fiber.
movq (%rsp), %rax
# Save the return address on the source stack.
pushq %rax
# Update the source stack pointer.
movq %rsp, (%rdi)
# Switch the stack pointer to destination stack.
mov %rsi, %rsp
# This will return to the destination fiber.
retq
Then, we need a very simple fiber implementation, with the only fiber context being its stack pointer.
main_fiber.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
#include <stdio.h>
#include <stdlib.h>
#define MAX_NUM 10
static int number = 0;
void init_run_context(void** stk_ptr, void* entry_point);
void switch_run_context(void** src_stk_ptr, void* dst_stk_ptr);
typedef struct fiber {
void* stk_ptr;
} fiber_t;
fiber_t fiber_odd;
fiber_t fiber_even;
void fiber_exit() {
exit(0);
}
void print_odd() {
while(number < MAX_NUM) {
if (number % 2 == 0) {
switch_run_context(&fiber_odd.stk_ptr, fiber_even.stk_ptr);
} else {
printf("%d ", number);
number++;
}
}
fiber_exit();
}
void print_even() {
while(number < MAX_NUM) {
if (number % 2 == 1) {
switch_run_context(&fiber_even.stk_ptr, fiber_odd.stk_ptr);
} else {
printf("%d ", number);
number++;
}
}
fiber_exit();
}
int main() {
char stk_odd[1024] = {0};
char stk_even[1024] = {0};
fiber_odd.stk_ptr = (void*)stk_odd + sizeof(stk_odd);
fiber_even.stk_ptr = (void*)stk_even + sizeof(stk_even);
init_run_context(&fiber_odd.stk_ptr, print_odd);
init_run_context(&fiber_even.stk_ptr, print_even);
print_odd();
// Should never reach here.
return 0;
}
As we can see, each fiber just yield (i.e. switch_run_context) to the other after printing and increasing the number. No synchronization mechanism is needed. Also note that I just call exit after each fiber finishes printing because this simplified implementation can’t return to main function.
To build and run the code:
1
2
$ gcc -o main_fiber main_fiber.c switch.S
0 1 2 3 4 5 6 7 8 9
This is just a proof-of-concept implementation of fiber with a lot of hardcoding. For a complete implementation of a fiber, see Rocket I/O.
io_uring
io_uring is a relatively new asynchronous I/O interface on Linux. It is currently the only asynchronous I/O back-end supported by Rocket I/O. There are already many good resources on the Internet talking about io_uring. I don’t think I can explain it better than others. I will just list a few that I found useful:
Rocket I/O
You can check out the code of Rocket I/O on Github.
Rocket I/O has three major components: rocket engine, rocket fiber and rocket executor.
Rocket Engine
Rocket engine is the asynchronous I/O back-end. The goal is to implement various engines such as epoll, aio, etc. But for now the only supported engine is io_uring.
A rocket engine mainly provides two interfaces: one to submit an I/O request and the other to get a complete I/O operation. When a fiber makes an asynchronous I/O call, it calls the submit interface and set the fiber state to blocked. Later, the executor will call the complete interface to get the completed result and wake up the fiber by setting its state to runnable.
Rocket Fiber
A rocket fiber is nothing but a fiber with the following contexts:
- Stack pointer.
- Callee-saved registers.
- Address of the next instruction.
- Executor where the fiber runs on.
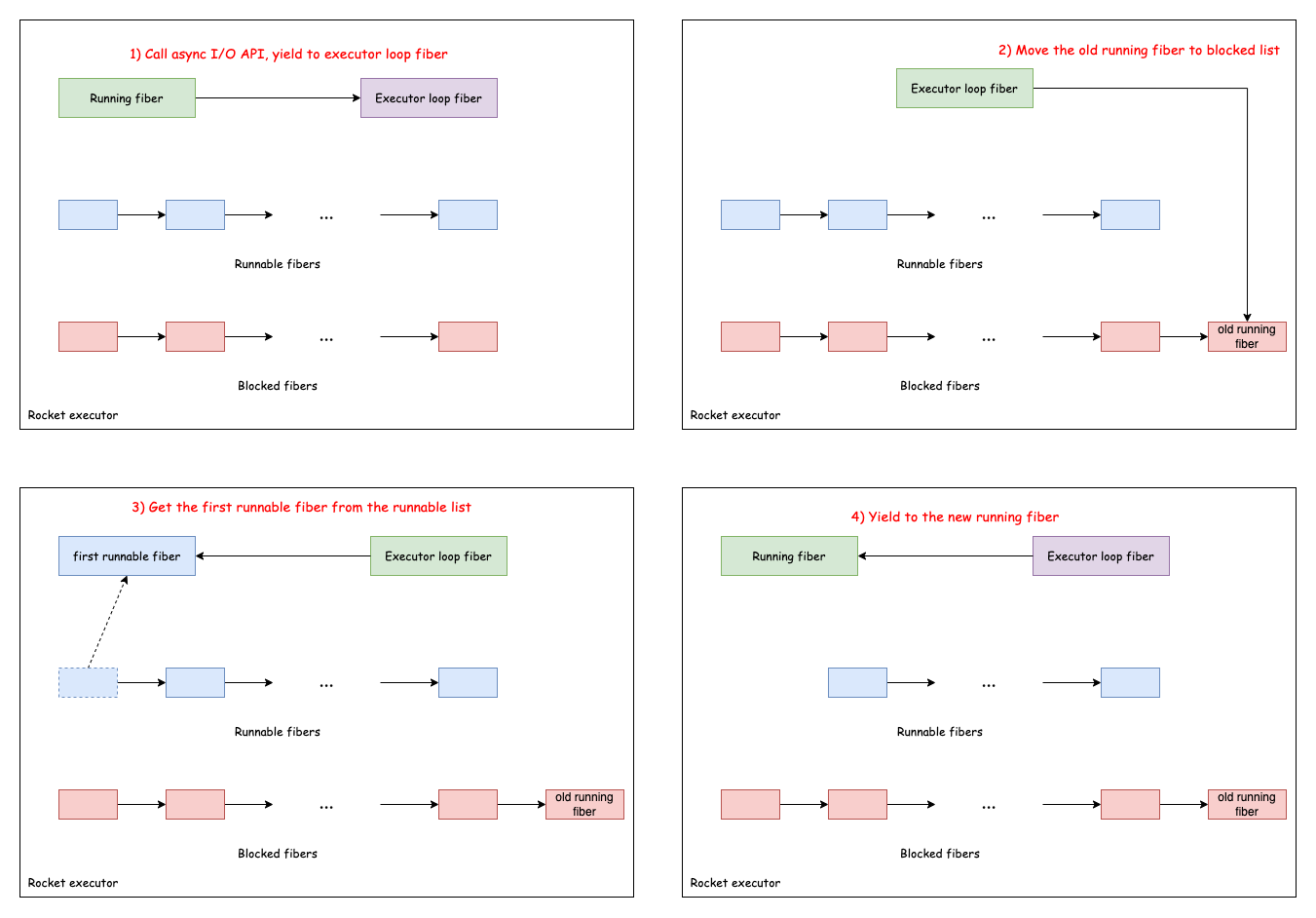
Rocket Executor
Rocket executor maintains a list of runnable fibers and a list of blocked fibers. When a fiber yields by calling an asynchronous I/O API, it saves current context and switch the context to the executor. The executor will pick the next runnable fiber and switch the context to it. If there is no runnable fiber at the moment, it tries to see if there are completed I/O operations. If so, then it unblocks a fiber by moving it from blocked fiber list to runnable fiber list. Next, it picks up the first runnable fiber in the runnable list to run.
Rocket I/O Benchmark
I wrote a banchmark for Rocket I/O v.s. pthread + synchronous I/O just to answer the question: Is fiber + asynchronous I/O really faster than multi-threaded synchronous I/O? Like mentioned before, with multiple threads, when one thread is encountering an synchronous I/O, it can be preempted, put into sleep and will wake up when the I/O is done. This seems similar to fiber with asynchronous I/O. Then is the latter really faster? Of course, this comparison is based on the assumption that there is only one CPU core, which means the multiple threads can run concurrently but not in parallel. In fact, there is a similar question on Stackoverflow.
In theory, I think the answer is yes because fiber is lighter than thread as we can see from the simple fiber implementation above. But I wasn’t 100% sure until I ran a benchmark to compare the performance between them with a simple echo server workload.
- pthread implementation
- The server accepts incoming connections in the main thread. For each client connection, it creates a new thread to handle the connection. Each thread is preempted by the thread scheduler on synchronous I/O.
- Rocket I/O impelementation
- The server accepts incoming connections in a fiber. For each client connection, it creates a new fiber to handle the connection. Each fiber yields to another runnable fiber on asynchronous I/O.
I used rust_echo_bench as the benchmark tool and borrowed the script from here. The result shows that fiber with asynchronous I/O has higher performance than pthread with synchronous I/O when both running on one CPU core.
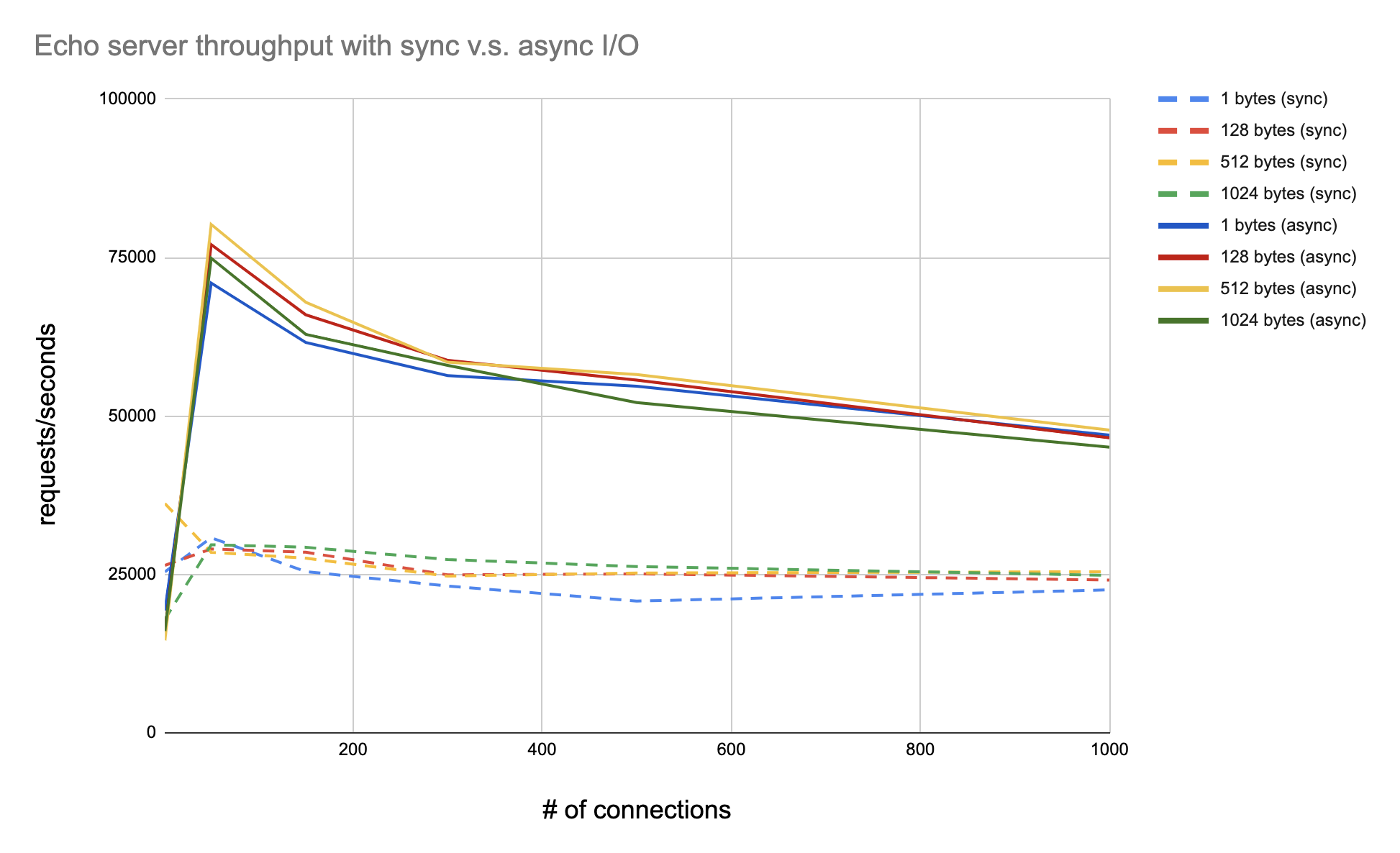
See Rocket I/O benchmark for more details.
Conclusion
In this post, I talked about asynchronous I/O, fiber and the design of Rocket I/O, an async runtime library. The benchmark shows that the performance of fiber with asynchronous I/O, specifically, with io_uring, is better than multithreaded synchronous I/O.
There are still more future work to do such as implementing more asynchronous I/O engines, cross-platform support, multithreading to fully utilize all CPU cores, etc. Feel free to contribute if you’re interested!
Comments powered by Disqus.