Summary
Our project uses Identifier-Locator Addressing (ILA) for IPv6. Recently, we noticed that traceroute doesn’t work well for SIR address. The problem is, though traceroute can reach ILA router and eventualy reach the ILA host, all the intermediate nodes between the ILA router and the ILA host are shown as “* * *”. This post is about the debugging process of the issue, the root cause and a potential fix.
Background
ILA
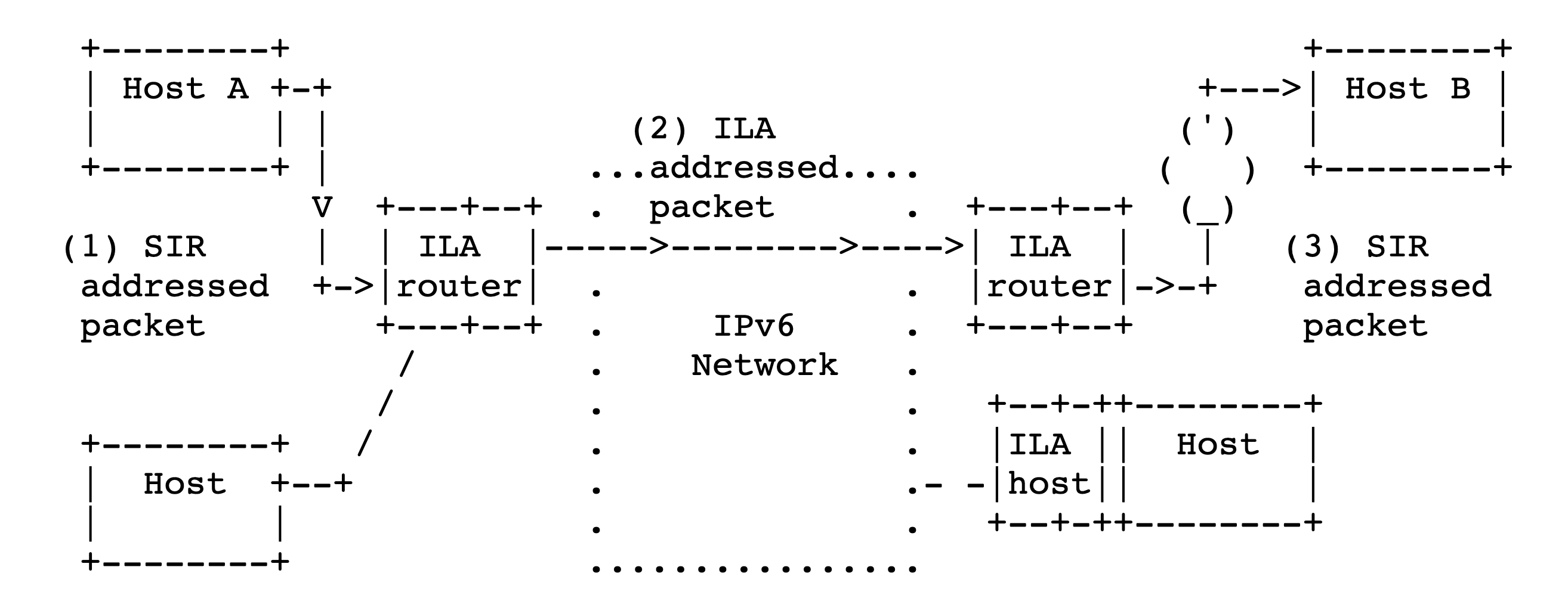
ILA is a virtual networking solution. It assigns a unique 64-bit identifier to each task in the data center. This identifier is location-independent and is tied to the task. When another task wants to communicate with an ILA-task, it sends packets with destination IPv6 address being 64-bit SIR (Standard Identifier Representation) prefix + 64-bit identifier.
An ILA router in the network translates this virtual IP (SIR address) into a physical IP (ILA address) and forwards packets to the physical host where the destination task runs. With ILA, no matter where the task moves to, its IPv6 address (SIR address) is never changed.
See Identifier-locator addressing for IPv6 for more information.
Traceroute
This is covered by traceroute man page and I will just copy it here.
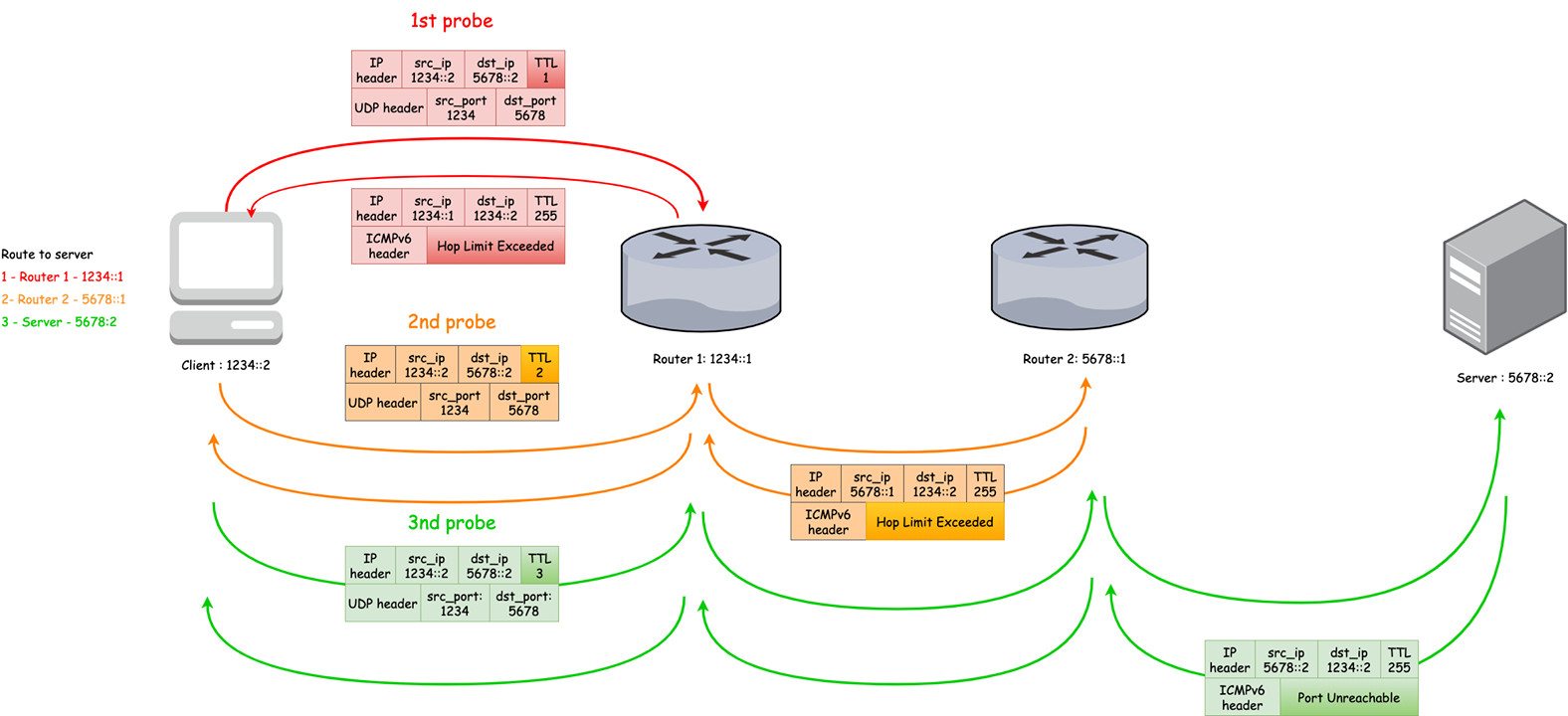
This program attempts to trace the route an IP packet would follow to some internet host by launching probe packets with a small ttl (time to live) then listening for an ICMP “time exceeded” reply from a gateway. We start our probes with a ttl of one and increase by one until we get an ICMP “port unreachable” (or TCP reset), which means we got to the “host”, or hit a max (which defaults to 30 hops).
Note, by default, traceroute on Linux uses UDP for probe packets.
Problem
While using traceroute to trace ILA packets, we found that intermediate hops between ILA router and the final destination are unknown (printed as “*”).
The output is something like:
$ traceroute6 <ILA task> -N 1 -q 1
traceroute to <ILA task> (<ILA task SIR address>), 30 hops max, 80 byte packets
1 <Top-of-Rack switch> (ToR IP) 0.224 ms
2 <hop 2> (<hop 2 IP>) 0.303 ms
3 <hop 3> (<hop 3 IP>) 0.303 ms
4 <hop 4> (<hop 4 IP>) 0.226 ms
5 <hop 5> (<hop 5 IP>) 0.272 ms
6 <hop 6> (<hop 6 IP>) 4.692 ms
7 <hop 7> (<hop 7 IP>) 0.263 ms
8 <hop 8> (<hop 8 IP>) 0.279 ms
9 <hop 9> (<hop 8 IP>) 0.437 ms
10 <ILA router> (<ILA router IP>) 0.200 ms
11 *
12 *
13 *
14 *
15 *
16 *
17 *
18 *
19 *
20 *
21 *
22 *
23 *
24 *
25 *
26 <ILA task> (<ILA task SIR address>) 53.374 ms
Debug
Setup
To reproduce and debug the issue, I set up a minimal environment with one ILA router, one ILA task and one traceroute host (TR host). They are all under the same rack. So an ILA packet’s route should be “TR host –> ToR –> ILA router host –> ToR –> ILA task host”.
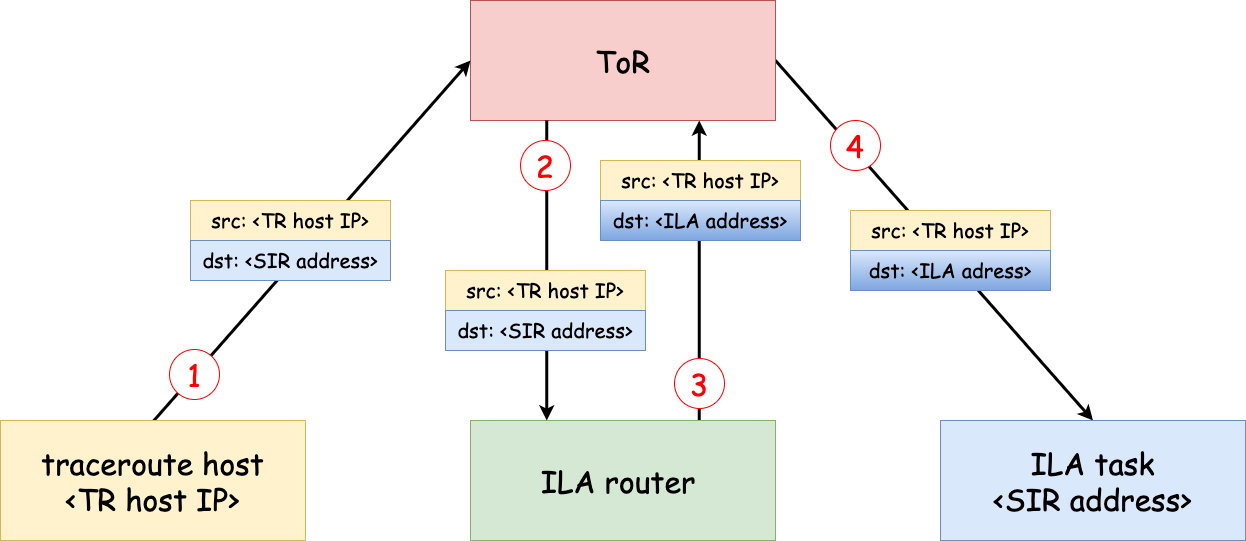
When traceroute the SIR address, I got
<TR host>$ traceroute <SIR address>
traceroute to <SIR address> (<SIR address>), 30 hops max, 80 byte packets
1 <ToR> (<ToR IP>) 0.214 ms 0.258 ms 0.325 ms
2 <ILA router> (<ILA router IP>) 0.080 ms 0.096 ms 0.071 ms
3 * * *
4 <ILA task> (<SIR address>) 0.179 ms 0.182 ms 0.171 ms
As we can see, the third hop, Top-of-rack switch, is missing from the output.
Wait, mtr works?
It was almost the end of the day and I really missed home so I didn’t spend much time debugging. Somehow I just decided to give mtr a shot and guess what? It worked!
My traceroute [v0.85]
<TR host> (::) Thu Mar 12 16:29:07 2020
Keys: Help Display mode Restart statistics Order of fields quit
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. <ToR IP> 0.0% 6 0.2 0.3 0.2 0.5 0.0
2. <ILA router IP> 0.0% 6 0.1 0.1 0.1 0.2 0.0
3. <ToR IP> 0.0% 6 0.2 0.3 0.2 0.4 0.0
4. <ILA task> 0.0% 6 0.2 0.2 0.2 0.3 0.0
The third hop, ToR, was printed as expected. So our solution was just using mtr instead of traceroute.
But WHY?
Even though we found an alternative, this annoying traceroute problem haunted me in my dream. The last scene before I woke up was endless tcpdump output, driving me to continue debugging.
I had some guesses and all I needed to do was to (dis)prove them.
Guess #1 - ICMPv6 Time Exceeded is not sent back by ToR
This is unlikely because otherwise mtr should also fail but I needed more evidence.
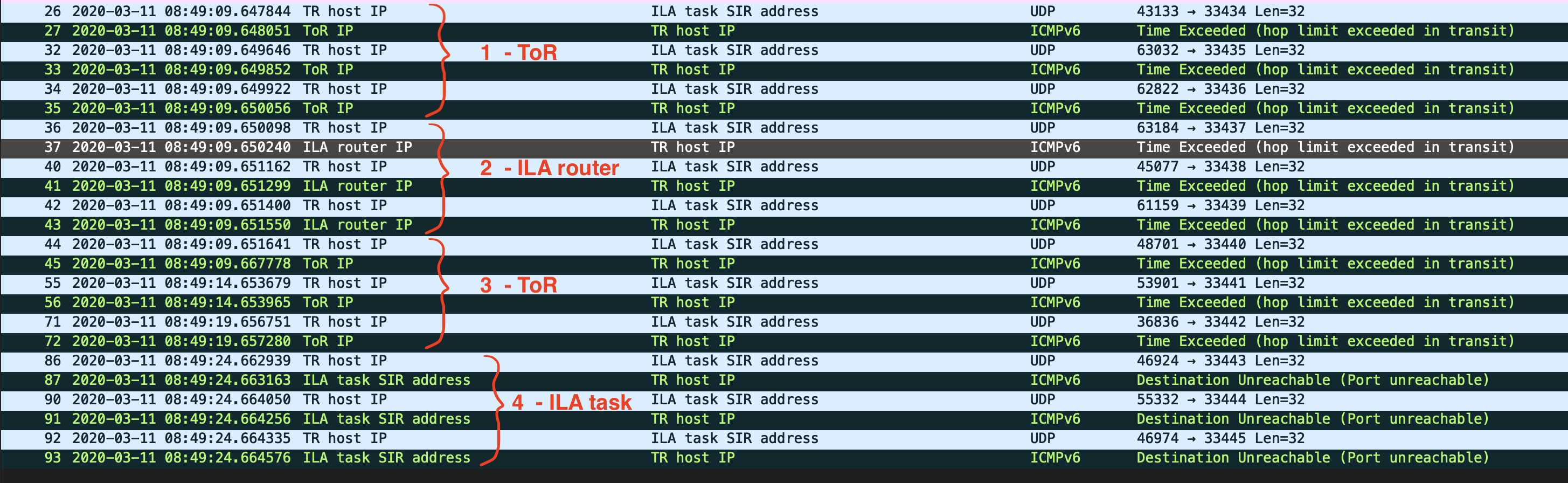
I ran tcpdump on all 4 nodes while running traceroute. The result disproved this theory. All UDP probe packets were sent and received as well as all ICMPv6 Time Exceeded packets. Below is the pcap file:
Guess #2 - traceroute uses UDP while mtr uses ICMP Echo
Because mtr works but traceroute doesn’t, it became a game of finding the difference between them.
We mentioned earlier that traceroute uses UDP as probe packets. Look at pcap result, it seems that mtr uses ICMP Echo (ping) as the default protocol.

Unfortunately, this is still not the reason because mtr with UDP (mtr <IP>
--udp) also works and the pcap result looks very similar to that of
traceroute.
Guess #3 - mtr uses UDP port to match probe/response while traceroute doesn’t
I then looked more closely into the packets in Wireshark. One interesting thing I noticed was, Wireshark pairs a UDP probe with its ICMPv6 Time Exceeded response when any of them is focused.

When I click the 3rd UDP probe, even Wireshark didn’t pair it with the ICMPv6 Time Exceeded response from the ToR. This made me wonder - how does Wireshark do the matching and could it be the same way as traceroute?
At this point, I had a strong feeling that the answer must reside in these UDP and ICMPv6 packets. I just needed to examine each and every bit. And here comes the next interesting finding - the ICMPv6 reply has an inner IP and UDP header.
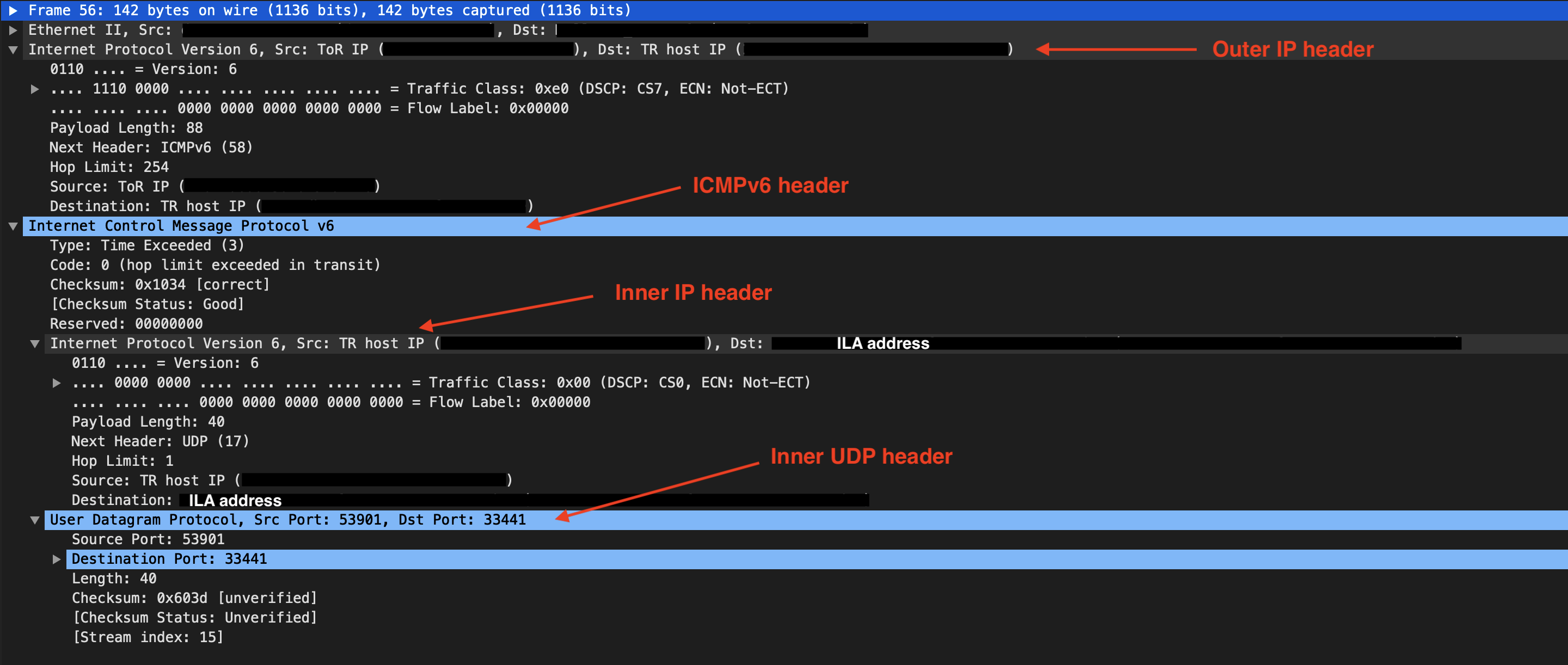
It seems that the ICMPv6 response embedded the original IP and UDP content as its body in order for sender to match it with the original request. Then I realized that it might because mtr only uses inner UDP port to associate ICMPv6 response with UDP probe yet traceroute as well as Wireshark uses src/dst IPs in the inner IP header + UDP port.
The first half of the theory was easily proved by reading mtr code.
As the name implies,
handle_inner_udp_packet
is called to handle inner UDP packet. It calls
find_probe
to match this UDP with an outstanding probe. And It first tries to find a
match with dstport and then srcport and then checksum. Any information
in the inner IP header is not used. Nice! This puzzle is 50% solved.
Next, I only needed to read some traceroute code and confirm that it uses inner IP for the matching (Thankfully, both tools are open-sourced). Simple task, huh? Well, the reality always lets us down. After spending some time going through traceroute code, I still couldn’t find such logic. This line suggested that it also only uses UDP port to do the matching. And I was pretty sure the version of the code I looked at was the same as the version of traceroute run.
Because I was too lazy to continue reading the code, I started using gdb to trace the code. After some tedious debugging with gdb, I finally got something.
Here,
poll function is called to determine whether a response is received. If its
return value is larger than 0, then
recvmsg
will be called to receive actual data. However, the breakpoint at recvmsg was
hit only 3 times and it wasn’t hit when the Time Exceeded message from ToR was
received. That means, poll didn’t detect the message on the socket. This
also implies that the inner IP matching might be done in the kernel, who
decides not to send the packet to the socket.
But why does kernel only do this to traceroute but not mtr???
Guess #4 traceroute does something irritating and kernel hates it
With above findings in mind, I came back to the game of finding the difference
between mtr and traceroute code. That was when I noticed this
line
- udp_send_probe calls connect syscall on the UDP socket. This looked
very strange to me. As we all know, UDP is a connectionless protocol. Why does
it even need to call connect?
According to connect syscall man
page,
The connect() system call connects the socket referred to by the file descriptor sockfd to the address specified by addr.
AND
Generally, connection-based protocol sockets may successfully connect() only once; connectionless protocol sockets may use connect() multiple times to change their association.
That means, a connectionless protocol like UDP can also call connect() to
associate the socket with an address. And traceroute calls it to associate the
UDP socket with destination address, which is the SIR address. Thus, when the
response has an ILA address in its inner IP header, it is not sent to the socket! (I
didn’t read specific kernel code here. I’d appreciate it if anyone can point me
to relevant code.)
Now the puzzle is fully solved!
How to make traceroute work?
Knowing the root cause, the fix is rather easy. I have a simple patch:
$ git diff
diff --git a/traceroute/mod-udp.c b/traceroute/mod-udp.c
index f3bdead..e2997ab 100644
--- a/traceroute/mod-udp.c
+++ b/traceroute/mod-udp.c
@@ -134,15 +134,15 @@ static void udp_send_probe (probe *pb, int ttl) {
set_ttl (sk, ttl);
- if (connect (sk, &dest_addr.sa, sizeof (dest_addr)) < 0)
- error ("connect");
+ //if (connect (sk, &dest_addr.sa, sizeof (dest_addr)) < 0)
+ // error ("connect");
use_recverr (sk);
pb->send_time = get_time ();
- if (do_send (sk, data, *length_p, NULL) < 0) {
+ if (do_send (sk, data, *length_p, &dest_addr) < 0) {
close (sk);
pb->send_time = 0;
return;
diff --git a/traceroute/traceroute.c b/traceroute/traceroute.c
index 4be9b24..5c451b5 100644
--- a/traceroute/traceroute.c
+++ b/traceroute/traceroute.c
@@ -1637,7 +1637,7 @@ void set_ttl (int sk, int ttl) {
int do_send (int sk, const void *data, size_t len, const sockaddr_any *addr) {
int res;
- if (!addr || raw_can_connect ())
+ if (!addr)
res = send (sk, data, len, 0);
else
res = sendto (sk, data, len, 0, &addr->sa, sizeof (*addr));
After rebuilding traceroute, it works well for SIR address now:
$ make
$ ./traceroute/traceroute <ILA task SIR address> -N 1 -q 1
traceroute to <ILA task SIR address> (<ILA task SIR address>), 30 hops max, 80 byte packets
<... Unrelated hops ...>
23 <ILA router> (<ILA router IP>) 163.952 ms
24 <ToR> (<ToR IP>) 163.857 ms
25 <ILA task> (<ILA task SIR address>) 163.132 ms
However, I would guess that this is a “feature” instead of a “bug” because
otherwise why did the genius author of traceroute choose to call
connect() on a UDP socket? I just don’t understand the reason behind it.

Resources
[1] Identifier locator addressing
[2] Identifier-locator addressing for IPv6
[3] traceroute man page
